
BLOGUE
Ceux qui ont déjà conduit un ponton ont probablement découvert que ce n’est pas comme se déplacer en canot. Lorsque l’on tourne le volant, le ponton continue sa lancée un moment avant que l’on puisse observer le changement de direction. Afin d’ajuster le cap de façon optimale, il vaut mieux se fier à la trajectoire projetée sur le tableau de bord plutôt qu’à la trajectoire courante du bateau. Sans quoi le résultat est un parcours chaotique et sinueux qui nuira à l’appréciation du paysage et mettra en péril le voyage. On peut faire plusieurs parallèles entre cette image et l’évolution d’un projet de développement logiciel.
L’avantage des équipes et des projets de petite taille est de pouvoir pivoter rapidement. Un peu comme à bord d’un canot, l’impact de ne pas ramer au même rythme est plus flagrant, en raison du nombre limité de chantiers en cours et de collègues pour réviser le code. Cependant, lorsque la taille de l’équipe augmente, ça devient comparable à un poids lourd sur l’eau et il est facile de perdre le fil. Plus il y a de fichiers, plus ça demande du temps afin de refléter une nouvelle pratique sur le système. Plus il y a de personnes, plus ça demande de la rigueur afin de rester aligné et de partager une compréhension commune des concepts.
Généralement, on doit être patient et motivé pour apporter un changement, car cela implique tous les contributeurs de l’équipe. L’effort d’une seule personne qui, de toutes ses forces, nage pour redresser la trajectoire d’un navire ne représente pas une solution durable. Tôt ou tard, cette personne se trouvera inévitablement épuisée. Les améliorations de l’équipe ne devraient pas reposer sur les épaules d’une seule personne. D’autant plus que ça ne favorise pas le transfert des connaissances essentiel afin de rester aligné et de ne pas répéter les mêmes erreurs. En d’autres mots, le superhéros de l’équipe ne peut pas sauter à l’eau chaque fois que l’équipe aura tourné le moteur dans une autre direction.
Alors, comment s’assurer de garder le cap en équipe sans interrompre la livraison de valeur? Comment vivre avec l’état actuel du projet tout en s’assurant que le code modifié ou ajouté dans le futur respecte les décisions prises? Dans le texte qui suit, nous explorerons certaines pistes de solution.
Exploiter les analyses statiques dans une équipe de développement
Connaissez-vous les analyses statiques? Ce sont des méthodes qui, quel que soit le langage, permettent de valider certains aspects d’un logiciel sans réellement l’exécuter. Pour illustrer avec un exemple simple, en JavaScript, on peut créer une chaîne de caractères à l’aide de guillemets simples ou doubles. Cela est visible facilement en lisant le code. Une équipe peut décider de définir un standard en ajoutant une règle qui fait respecter l’utilisation d’un même type de guillemet à travers le projet.
En revanche, ça ne sert pas qu’à définir des aspects plus visuels comme le choix des guillemets! Il existe un grand nombre de règles à configurer pour éviter de mauvaises pratiques ou respecter des décisions architecturales, entre autres, des règles d’obsolescence (deprecation) et de restriction de dépendances (imports). Dans ces deux cas, on peut même configurer un message pour indiquer par quoi remplacer l’utilisation fautive.
Pour illustrer, admettons que nous travaillons sur un livre de recettes numérique. En équipe, nous avons déterminé trois concepts :
- Le livre de recettes, recipeBook, qui permet de lister les recettes.
- Les formulaires de recette, recipeForm, qui permet d’entrer une nouvelle recette dans le livre.
- Les recettes, recipe, en lecture seulement, qui permettent d’afficher les ingrédients et les étapes de réalisation.
Nous avons également déterminé que les recettes peuvent exister de façon indépendante et qu’elles ne doivent pas dépendre des deux autres concepts.
Avec ESLint, on peut gérer les dépendances entre les concepts. La décision que l’on vient de prendre dans notre projet fictif peut se traduire de cette façon dans le .eslintrc :
module.exports = {
"overrides" : [
{
"files" : [
"./src/recipe/*" // For any file in recipe
],
"rules": {
"no-restricted-imports": [
"error",
{
"patterns": [
{
"group": [
"*/recipeBook/*" // Forbid imports from recipeBook
],
// You can also specify a message that will be displayed beside the error
"message": "Recipe should not depend on RecipeBook"
},
{
"group": [
"*/recipeForm/*" // Also forbid imports from recipeForm
],
"message": "Recipe should not depend on RecipeForm"
}
]
}
]
}
}
]
}
Imaginons qu’après une journée particulièrement éprouvante, votre collègue, dont la concentration est affaiblie, se mette à travailler sur le livre de recettes. Peut-être qu’il devrait plutôt fermer son ordinateur, mais demain étant vendredi et annonçant du beau temps, il sait pertinemment qu’il n’aura pas envie de reprendre les heures non complétées la journée précédente. Ses yeux commencent à lui jouer des tours et il place la nouvelle page dans le répertoire des recettes par erreur.
S’il a configuré son IDE avec ESLint, il verra presque aussitôt l’erreur avec le message explicatif que nous avons configuré. Si ce n’est pas le cas, il le verra lorsque le pipeline échouera, ce qui empêchera d’intégrer l’erreur au reste du code.
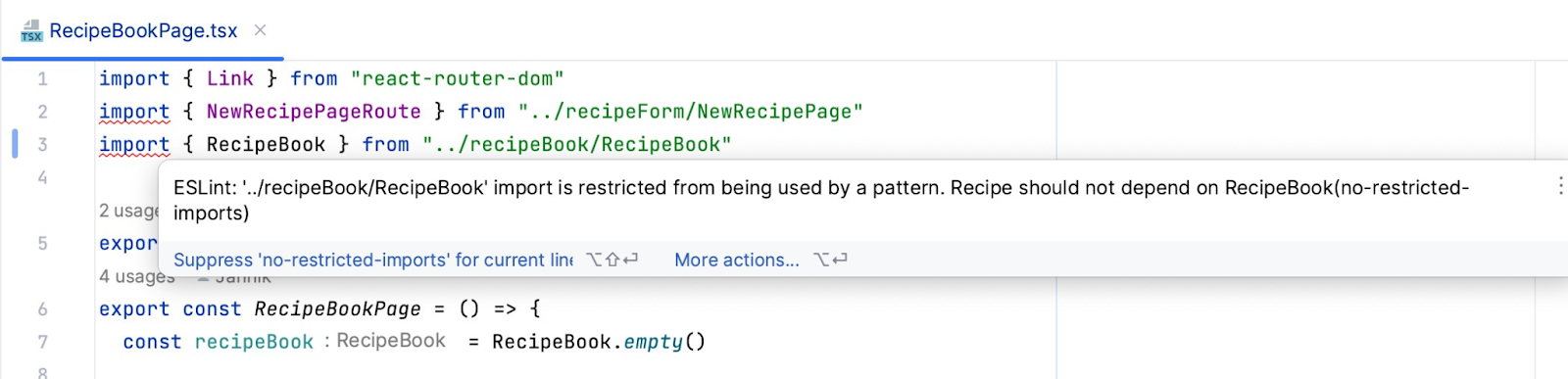
Le message ci-dessus nous indique que l’on importe des fichiers en lien avec le livre de recette, ce qui peut être un signe que ce répertoire est un meilleur endroit pour placer cette nouvelle page.
Voici un autre exemple avec la même application, mais cette fois-ci, nous avons déterminé des couches à respecter :
- ui, qui s’occupe de la présentation.
- domain, qui s’occupe des concepts clés et de la logique associée.
- api, qui s’occupe de faire les appels HTTP au serveur et de traduire les réponses en concepts de la couche domain.
Tout comme l’exemple précédent, on peut ajouter les règles et même rappeler le rôle des couches à l’aide des messages. Voilà une configuration possible pour la couche api :
module.exports = {
"overrides" : [
{
"files" : [
"./src/*/api/*"
],
"rules" : {
"no-restricted-imports" : [
"error",
{
"patterns" : [
{
"group" : [
"**/ui/*"
],
"message": "The api layer has the responsibility to make the HTTP calls and return domain objects to the application. It should not depend on the ui layer."
}
]
}
]
}
}
]
}
Cette fois-ci, un différent contributeur qui était parti en vacances et qui a manqué la discussion sur les couches commence à travailler sur l’ajout d’une nouvelle recette. Il écrit le client qui permet d’envoyer le formulaire au serveur et a l’idée de retourner la page qui présente la recette au complet plutôt que de retourner seulement la recette. Ici, non seulement l’erreur indique que c’est interdit, mais elle donne également un bon indice pour résoudre le problème, soit le fruit des discussions qu’il a manquées lors de son voyage de pêche.

S’ajuster en milieu de projet
Supposons que le projet suit son cours depuis un certain temps. Le système s’est considérablement développé, et avec lui, le désordre a également pris de l’ampleur. Les nouveaux membres qui se joignent ont beaucoup de mal à comprendre et l’équipe décide que c’est le moment de faire un grand ménage. Elle discute des améliorations possibles et définit une nouvelle structure adaptée aux besoins actuels.
Cependant, avec ESLint, on a souvent le réflexe de configurer l’outil d’analyse sur le dossier source du projet pour des raisons de simplicité. Si l’équipe ajoute de nouvelles validations au pipeline afin de respecter la nouvelle structure du projet, il y aura un grand nombre d’erreurs à régler d’un seul coup. C’est donc un changement dispendieux et risqué.
Heureusement, à la différence des validations dynamiques qui exigent l’exécution du code, telles que les tests, les analyses statiques permettent de se concentrer uniquement sur les lignes de code modifiées. Ainsi, seuls les changements apportés peuvent entraîner un résultat différent par rapport à la version précédente. Cela fait en sorte que l’on peut limiter ces validations aux fichiers changés. En pratique, il s’agit de construire une commande Git qui sort la liste des changements et de passer celle-ci en paramètre à ESLint.
Le fait d’analyser seulement les changements permet maintenant d’intégrer de nouvelles règles en milieu de projet sans devoir repasser sur tout le système pour les appliquer lors de l’ajout. Les nouvelles décisions seront appliquées au fur et à mesure que les fichiers seront modifiés. Ça revient à appliquer le principe de la règle du scout, soit de laisser le code dans un meilleur état que celui dans lequel on l’a trouvé.
On doit néanmoins garder en tête que la correction de certaines règles à certains endroits peut engendrer plus de changements que prévu et augmenter le nombre de fichiers changés. Pour cette raison, on doit apprendre à choisir ses batailles et analyser l’impact d’une règle avant de l’ajouter.
Prenons l’exemple d’une équipe qui a importé une des dépendances un peu partout dans le projet, et qu’elle décide de l’encapsuler progressivement pour être mieux protégée dans le futur. Elle a déjà créé une abstraction qui s’occupe d’appeler la librairie et d’exposer le nécessaire. L’ajout d’une règle qui empêche l’import de la dépendance à l’extérieur de l’abstraction n’a pas un gros impact. En effet, il suffit de remplacer l’utilisation de la librairie par la nouvelle interface chaque fois que l’on rencontre une erreur. Par contre, la même équipe a la mauvaise habitude de forcer des types à l’aide du mot-clé as en TypeScript. Elle se retrouve dans une situation où c’est difficile de savoir si l’on manipule réellement les bons types et décide d’ajouter une règle qui interdit le casting. L’ajout de cette règle a un plus grand impact, car c’est plus de l’ordre du cas par cas et les erreurs rencontrées sont potentiellement des problèmes difficiles à régler.
Une vision technique commune dans l’équipe de développement
Avec l’automatisation des validations d’architecture et la possibilité de les intégrer au pipeline, la responsabilité de respecter les décisions architecturales et d’appliquer les changements progressifs est désormais répartie au sein de toute l’équipe. C’est impossible d’intégrer du code qui viole ces règles. Ainsi, elles deviennent une sorte de contrat technique auquel chaque membre de l’équipe doit adhérer.
Ensuite, si un membre de l’équipe rencontre un obstacle et que l’architecture actuelle est incompatible avec la solution à implémenter, ce sera plus facile pour cette personne de lancer une discussion avec les autres membres pour revoir le contrat plutôt que de prendre un raccourci interdit. Cela permet à la fois à ce membre de livrer une solution plus durable, mais également aux autres membres de l’équipe de rester au courant des grands changements dans le projet.
Cette pratique permet également d’éviter son lot de soucis lors des révisions de code. Ayant délégué plus de validations aux machines, l’équipe peut concentrer ses efforts sur les problèmes auxquels elle n’a pas encore trouvé de solution ou qui sont plus de l’ordre du cas par cas. Cela contribue à amener le projet à un niveau supérieur et à générer de nouvelles discussions, plutôt que de devoir surveiller des aspects déjà discutés, mais que l’on oublie de temps à autre. En économisant le temps et la charge mentale associés aux règles automatisables, l’équipe augmente également ses chances de détecter d’éventuels problèmes dans les nouveaux changements apportés.
De plus, l’exercice d’automatiser une décision d’architecture aide à éliminer certaines confusions et favorise une meilleure communication. La compréhension d’une idée peut varier d’une personne à l’autre même après l’avoir documentée. Est-ce parce que personne ne lit la documentation? Est-ce parce qu’une partie de l’équipe mélange le sens des flèches de dépendance dans les diagrammes? Est-ce parce qu’on a accidentellement utilisé les mauvais termes techniques? Dans tous les cas, l’interprétation de la machine est unique. Par conséquent, les membres de l’équipe se rendent compte qu’ils ne se sont pas compris dès la première incohérence, et peuvent ainsi relancer la discussion plus rapidement pour ajuster la règle ensemble selon les résultats souhaités.
En conclusion
Les analyses statiques sont un bon outil pour créer des validations qui favorisent le respect des décisions d’équipe. De plus, elles permettent une diminution des refactorings puisque nous effectuons le remboursement de dettes techniques graduellement en même temps que l’ajout de valeur. Elles sont comme un guide qui aide l’équipe de développement actuelle et future à augmenter l’uniformité du code dans le projet tout en transférant certaines connaissances. Si l’équipe sait où elle veut aller, elle peut configurer la destination souhaitée sur son tableau de bord, et voir le tout s’ajuster peu à peu avec le temps. Tout en continuant de livrer de la valeur de façon plus efficiente.