
BLOGUE
Anyone who's ever driven a pontoon boat will have discovered that it's different from moving around in a canoe. When you turn the steering wheel, the pontoon continues on its course for a while before you notice the change in direction. To adjust the course optimally, it's best to rely on the projected trajectory on the dashboard rather than the boat's current course. Otherwise, the result is a chaotic, winding course that will detract from enjoying the scenery and jeopardize the trip.
There are several parallels to draw between this image and the evolution of a software development project. The advantage of small teams and projects is their ability to pivot quickly. Rather like a canoe, the impact of not rowing at the same pace is more pronounced due to the limited number of ongoing projects and developers reviewing the code. However, when the size of the team increases, it becomes comparable to a heavy weight on the water, and it's easy to lose the thread. The more files there are, the more time it takes to reflect a new practice on the system; the more people there are, the more rigour it takes to stay aligned and have a common understanding of concepts.
Generally speaking, it takes patience and motivation to bring about change because it involves all the team's contributors. A single person swimming with all their might to right a ship's course is not a sustainable solution. Sooner or later, that person will inevitably burn out. Team improvement should be on more than one person's shoulders, especially to encourage the transfer of knowledge, which is essential to staying aligned and not repeating the same mistakes. In other words, the team's superhero can't jump into the water whenever the team turns the engine in another direction.
So, how do you ensure your team stays on course without interrupting value delivery? How do you live with the project's current state while ensuring that code modified or added in the future respects the decisions made? In the following text, we explore some possible solutions.
Exploiting static analyses in development teams
Well, have you heard of static analysis? These are methods for validating certain aspects of software without actually running it, regardless of the language. To illustrate with a simple example, creating a character string using single or double quotation marks in Javascript is possible. This is visible simply by reading the code. A team may decide to define a standard by adding a rule that enforces the use of the same type of quotation mark throughout the project.
On the other hand, it's not just a matter of defining more visual aspects, such as the choice of quotation marks! Many rules must be configured to avoid bad practices or respect architectural decisions, including deprecation and dependency restriction rules (imports). In both cases, it is even possible to configure a message to indicate what to replace the faulty usage with.
Let's say we're working on a digital cookbook. As a team, we have determined three concepts:
- recipeBook, for listing recipes.
- Recipe forms, recipeForm, are used to enter new recipes into the book.
- A read-only recipe displays ingredients and steps involved in recipe creation.
We also decided that recipes can exist independently and must not depend on the other two concepts.
With ESLint, it's possible to manage dependencies between concepts, and the decision we've just made in our fictitious project can translate in this way in .eslintrc:
module.exports = {
"overrides": [
{
"files": [
"./src/recipe/*" // For any file in recipe
],
"rules": {
"no-restricted-imports": [
"error",
{
"patterns": [
{
"group": [
"*/recipeBook/*" // Forbid imports from recipeBook
],
// You can also specify a message that will be displayed beside the error
"message": "Recipe should not depend on RecipeBook"
},
{
"group": [
"*/recipeForm/*" // Also forbid imports from recipeForm
],
"message": "Recipe should not depend on RecipeForm"
}
]
}
]
}
}
]
}
Let's imagine that, after a particularly demanding day, an employee whose concentration is flagging starts working on the recipe book. He should probably shut down his computer instead, but tomorrow is Friday, and the weather is fine, so he knows he won't want to take up his hours again. His eyes start to play tricks on him, and he accidentally places the new page in the recipe directory.
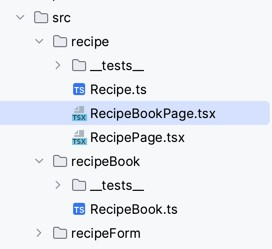
If he has configured his IDE with ESLint, he will almost instantly see the error with the explanatory message we have configured. If not, he'll see it when the pipeline fails, preventing the error from being integrated into the rest of the code.
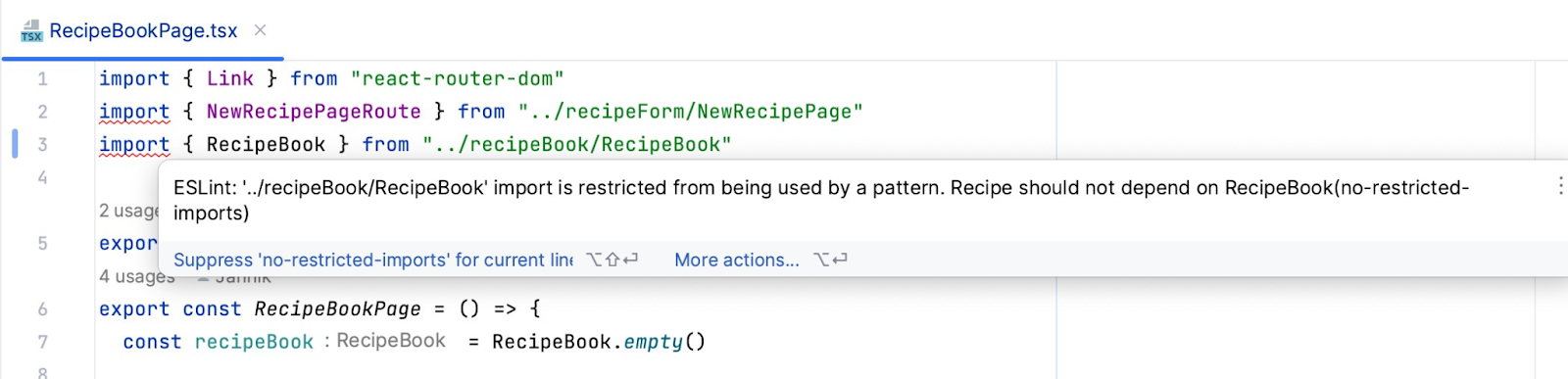
The message tells us we're importing files related to the recipe book, which may indicate that this directory is a better place to place this new page.
Here's another example with the same application, but this time, we've determined the layers to be respected:
- ui, which takes care of the presentation
- domain, which handles key concepts and associated logic
- api, which makes HTTP calls to the server and translates responses into domain layer concepts.
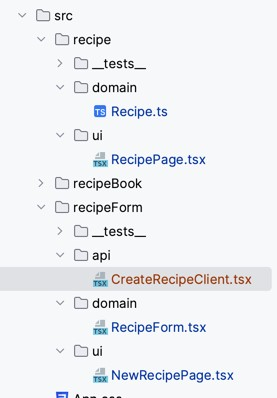
As in the previous example, adding rules and even reminding layers of their role using messages is possible. Here's a possible configuration for the api layer:
module.exports = {
"overrides": [
{
"files": [
"./src/*/api/*"
],
"rules": {
"no-restricted-imports": [
"error",
{
"patterns": [
{
"group": [
"**/ui/*"
],
"message": "The api layer has the responsability to make the HTTP calls and return domain objects to the application. It should not depend on the ui layer."
}
]
}
]
}
}
]
}
This time, a different contributor who was away on vacation and missed discussing the layers starts working on adding a new recipe. He writes the client that allows the form to be sent to the server and has the idea of returning the page that presents the entire recipe rather than just the recipe. Here, the error indicates that this is forbidden and gives an excellent clue to solving the problem - the fruit of the discussions he missed while on his fishing trip.

Adjusting mid-project
Let's assume that the project has been underway for some time. The system has grown considerably, and so has the clutter. The new members who join need help understanding, and the team decides it's time for a clean-up. They discuss possible improvements and define a new structure adapted to current needs.
However, with ESLint, the reflex is often to configure the analysis tool on the project's source folder for simplicity. If the team adds new validations to the pipeline to respect the new project structure, they will need to resolve many errors simultaneously. It's an expensive and risky change.
Fortunately, unlike dynamic validations, which require code to be executed, such as tests, static analyses allow you to focus only on the modified lines of code. In this way, only the changes can lead to a different result than the previous version. As a result, these validations can be limited to the changed files. In practice, this involves building a Git command that outputs the list of changes and passing it as a parameter to ESLint.
By analyzing only the changes, new rules can now be integrated mid-project without having to go through the whole system again to apply them when they are added. The latest decisions will be applied as the files are modified, which amounts to using the scout rule, i.e., leaving the code in a better state than the one you found.
However, it's essential to remember that correcting specific rules in certain places can lead to more changes than expected and increase the number of files changed. For this reason, you must learn to choose your battles and analyze the impact of a rule before adding it.
Let's take the example of a team that has imported one of its dependencies throughout the project and has decided to encapsulate it progressively for better protection in the future. They've already created an abstraction that calls the library and exposes what's needed. Adding a rule forbidding the import of the dependency outside the abstraction has little impact since it's enough to replace the use of the library with the new interface each time it encounters an error. On the other hand, the same team has a bad habit of forcing types using the as keyword in TypeScript. They find themselves in a situation where it's difficult to know if they're manipulating the right types and decide to add a rule prohibiting casting. Adding this rule has a more significant impact, as it's more of a case-by-case basis, and the errors encountered are potentially tricky problems to solve.
A shared technical vision within the development team
With the automation of architecture validations and the ability to integrate them into the pipeline, the responsibility for respecting architectural decisions and applying progressive changes is now distributed across the team. Integrating code that violates these rules is impossible. In this way, they become a technical contract to which everyone must adhere.
Then, suppose a team member encounters an obstacle, and the current architecture is incompatible with the solution he needs to implement. In that case, it will be easier for him to initiate a discussion with the other members to review the contract rather than take a forbidden shortcut. This enables the member to deliver a more durable solution and keeps the other team members abreast of significant changes in the project.
This practice also takes some of the hassle out of code reviews. Having delegated more validations to the machines, the team can focus on problems for which it has yet to find a solution or that are more of a case-by-case nature. This helps take the project to the next level and generate new discussions rather than monitoring aspects the team has already discussed and, occasionally, forgotten. By saving the time and mental load associated with automatable rules, the team also increases its chances of detecting potential problems in new changes.
What's more, automating an architectural decision helps eliminate confusion and promotes better communication. Understanding an idea can vary from person to person, even after being documented. Is it because no one reads the documentation? Is it because part of the team is mixing up the meaning of the dependency arrows in the diagrams? Is it because someone used the wrong technical terms accidentally? In all cases, the machine's interpretation is unique. As a result, team members realize they need help understanding each other at the first inconsistency and can get back to the discussion more quickly to adjust the rule according to the desired results.
In conclusion
Static analysis is a good tool for creating validations that help ensure that team decisions are respected. Moreover, it reduces the need for refactoring since we gradually pay off technical debts as we add value. It is like a guide that helps current and future developers increase project consistency while transferring specific knowledge. If the team knows where it wants to go, it can configure the desired destination on its dashboard and watch it gradually adjust over time while continuing to deliver value more efficiently.